
This post is a bit different. It’s theoretical, without any specific experiments. However, it may still be interesting in considering how some other biological neural networks process new knowledge.
This week, there were lectures and materials on various topics around decision trees, bagging, random forests, etc. Time series analysis was also included, but that felt like overkill.
A whole bunch of math was presented on how features are selected at each step of building a decision tree, including information gain, entropy, Gini index… I probably forgot half of it. It’s like being invited to a party where there are dozens of new people, being introduced to everyone, and then expected to remember each guest’s name. That’s not how biological brains work and learn. I’d be happy if I could memorize two or three new names.
But what really caught my attention and triggered further investigation was the magic number  It’s so beautiful, magical. But what does this number mean? It describes a property of bootstrapped datasets. Each data point from the original dataset has this chance of not appearing when doing a bootstrapped dataset. Bootstrapping means we create a variation, where we produce a dataset of equal size by randomly sampling data points from the original data to the new data. Each point can be represented in the new data twice, and each point can also be absent in the new bootstrapped data. Interestingly, there is only about a 60% chance that a given data point will be present in a new bootstrapped subset.
It’s so beautiful, magical. But what does this number mean? It describes a property of bootstrapped datasets. Each data point from the original dataset has this chance of not appearing when doing a bootstrapped dataset. Bootstrapping means we create a variation, where we produce a dataset of equal size by randomly sampling data points from the original data to the new data. Each point can be represented in the new data twice, and each point can also be absent in the new bootstrapped data. Interestingly, there is only about a 60% chance that a given data point will be present in a new bootstrapped subset.
So, there’s the decision tree, which is a machine model that predicts something based on other features. It’s quite intuitive, just like asking a bunch of questions. Are you older than 45? If yes, then are you a low income earner? If yes, do you live in a country with a weak public health service? If yes, then it’s probably true that you will die in the next 5 years. My example follows just one branch of this tree; it’s exhaustive, with follow-up questions for every “no.” but it is really easy to understood.
The problem with decision trees is that adding one more data point can greatly alter how the tree is generated. It’s a similar problem as in clustering… I mention clustering because it’s always in the back of my mind, and I have neither the time nor the faith that my idea for this algorithm will work in any reasonable way…
So, someone smart came up with the idea – let’s make a bunch of slightly different decision trees and average the results. That’s essentially what a random forest is – a set of random trees that are trained on similar data. But there’s one important caveat. For generating each new prediction tree, not only is the data bootstrapped, but the set of features is also limited. That got me thinking.
If applies to bootstrapping, then something similar applies to the selection of features. Now, it’s not the same, as we don’t select the same feature multiple times, and the size of the final subset is much smaller, but then my intuition connects this with the normal distribution where some features will be underrepresented, and others will be overrepresented. And if it’s all random, that means we can lose critical features.
So now’s the interesting part. Instead of looking at how it’s done, I started thinking… How would I solve this? So I came up with a simple algorithm where we have an initial set of features ![\mathbf{f} = [f_1, f_2, f_3, \ldots, f_N]](https://aulendil.net/hallucinations/wp-content/ql-cache/quicklatex.com-b66619c8bf2a03d1f5422ee124900e7d_l3.png "Rendered by QuickLaTeX.com") If we randomly select
If we randomly select  for each tree, we get a non-uniform distribution of features along the trees, which means some of them (maybe crucial ones) will be underrepresented. So it looks like the distribution of features should be uniform – each feature should be used approximately the same number of times among the forest. This would not only reduce the risk of underrepresenting crucial features but also would make trees more diverse, which is very desired in a random forest.
for each tree, we get a non-uniform distribution of features along the trees, which means some of them (maybe crucial ones) will be underrepresented. So it looks like the distribution of features should be uniform – each feature should be used approximately the same number of times among the forest. This would not only reduce the risk of underrepresenting crucial features but also would make trees more diverse, which is very desired in a random forest.
Now, instead of checking if it’s done and how it’s done in the world, I went my way – how to sample features so that they are uniformly distributed. The algorithm may be quite straightforward and simple:
… Hmm… it was to be theoretical, but then just describing a few lines of code without running them… Another opportunity to work a little bit with Python, so here is the repository.
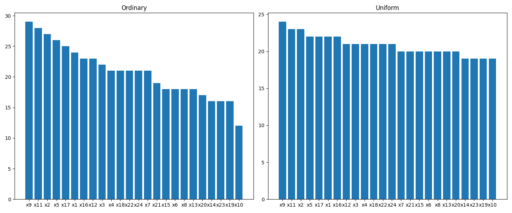
Yes, the uniform subsampling works fine. The next step should be checking if a random forest with such an adjustment performs better.
But the whole point of this post is a bit different. It’s just a meditation on how my learning process goes. Instead of accepting input and memorizing it, I go slow. I try to predict what it means, to test, then I compare my predictions with actual… with something. Is it consistent? Does it match other knowledge I have? The difference between my predictions and the actual something (in an ideal world, I’d confront my predictions with other people’s results, but that would be even more time-consuming)… so this difference is what really matters. Should I remember it, is it worthy, should I adjust my understanding, should I throw it away…
Two interesting thoughts arise. I believe that’s not how other people learn. My learning path is slow, especially in the short term. Once I heard the nice term “strategic learning,” so maybe that is what it is? Is my way efficient, good, does it make sense?
Second is that it’s another similarity between how my biological brain learns and how it’s done by machines. I find prediction error and adjust based on that. It’s exactly what is done in machine learning. Except I do that continuously, as a streaming machine, while computers learn and then do work – as a functional machine without memory… which is a topic for another post.”
One response to “Learning in random forest”
[…] my previous post, I explained that I was pondering the rather uneven distribution of features among the trees in a […]